前言
并发往往和并行一起被提及,但是我们应该明确的是“并发”不等同于“并行”
• 并发(concurrency) :同一时间段 对待多件事情 (逻辑层面)
• 并行(parallellism) :同一时刻 做(执行) 多件事情(物理层面)
在单核处理器,实际只有并发,同一时刻只能有一条指令执行,但多个进程的指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个执行单元快速交替的执行。
说到执行,就不能不提线程(thread),线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
但是在实际中,多线程大多是两个场景:
- 最顶层多线程,在程序启动的时候就开启了多线程,然后我们的逻辑代码是在每个线程里头执行的。
- 局部多线程,在我们的逻辑代码里,当我们有多个任务的时候,就开启多个线程去执行,执行完了就关闭了多线程。
第2种是我们最常用的场景,但是显然不够高效,频繁的开闭线程造成了不必要的损耗,而且对于持续的任务流并不友好,所以有个叫协程的东西出来了。
关于协程的定义,网上有很多,有抽象有具体,甚至还有带图的。但是很多时候读完还是让人一头雾水,觉得神秘又陌生。所以我们需要一个通俗易懂的解释。
以我本人的理解,协程就是是一种基于队列的任务调度机制,更详细的说,它是寄生于线程的任务执行队列,它是一种模式,并不是一种具体的方法。
协程就是线程里cpu去依次执行任务队列的任务,但是很多任务并不是能立刻执行完的,比如io操作,这时候cpu不能阻塞在这里,而是切换了下一个任务,而这个阻塞的任务交给另一个线程去执行(绝大多数情况下是交给内核线程)。
从这里可以看出,协程是一种高效利用cpu的机制,让线程在一段时间内执行更多的任务,但它对计算密集型的任务也没有太大的好处,计算密集型的任务本身不需要大量的线程切换,因此协程的作用也十分有限,反而还增加了协程切换的开销。好在我们日常的开发中,大部分是io密集型的,大部分的执行是文件读写或网络读写。
前面说了,协程是一种模式,不是一种方法,在具体的任务调度中,实现方式大体有两种
“分配式”任务调度模式
所谓的“分配式”,指的是任务创建的时候,就按一定的分配算法投递到子线程对应的任务队列里去了。每个子线程只执行自己对应的任务队列的任务,不涉及多线程任务争抢,避免了全局锁。这种模式操作简单,看起来"公平",是一种“平均主义”。但是动态调整性偏弱。
这种模式没有调度系统,实现简单,每个子线程是被动接受任务的,而且任务一旦被接受,就一直在这个线程内执行。比较知名的c++网络库muduo即是这种模式,每个线程都有一个eventloop,主线程accept一个fd后,就直接投递到子线程的执行队列里去了。
“抢占式”任务调度模式
与“分配式”不同,抢占模式在主线程或独立的线程维持了一个独立的任务队列,我们暂且将其称为主队列,任务创建的时候是是添加到这个队列的。子线程从这个主队列获取任务直接执行或加到自己的任务队列后再执行。这是一种"按劳分配"模式,典型的"能者多劳"。
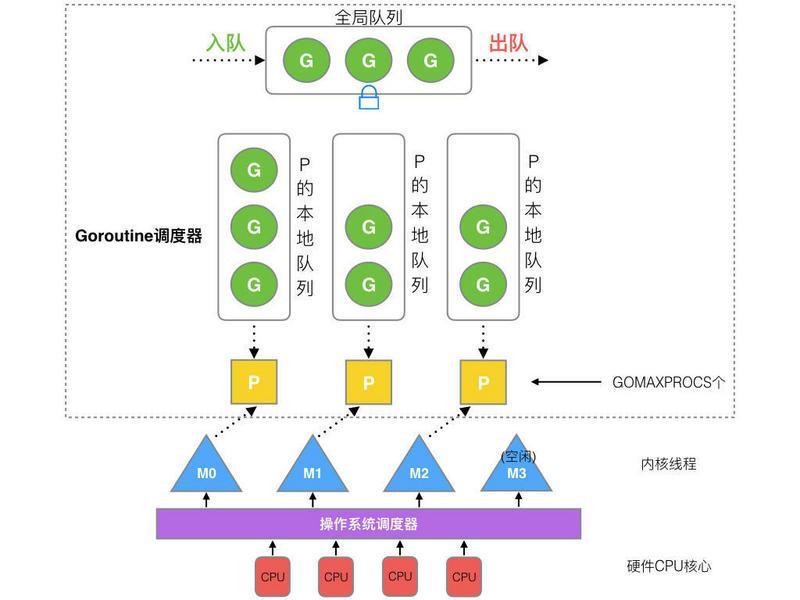
go的GMP就是典型的抢占式调度(Preemptive scheduling)
它与分配式相比最大的好处就是子线程(P, Processor)的利用率高。一旦子线程的任务队列里的任务过多,可以将其重新移到主队列里重新分配。这样实现了子线程的动态平衡。
值得注意的是,这里的"抢占"并不是说一定是子线程主动去主队列获取任务。调度器主动将任务投递到子队列也是抢占模式,抢占的意思只是与无差别平均分配模式对立。核心是是否是"平均主义"
在go里面,会有一个调度器来维持子队列的平衡。其过程如下图(图片来自网络,出处不可考)
最后,任务是什么?
前面无数次提到了任务一词,但是“任务”到底是什么呢?我们在网上看到的介绍里,上下文(context),栈(stackless/stackfull)这些概念又去了哪里呢?
纯用户代码层面模拟的“协程”
前面说的都是我们自己模拟的"协程"。我们先从队列取出“任务“,从“任务”里解析出必要的参数,然后用特定的函数去执行就行了。这里的执行函数是我们自己定义的。它是针对具体问题的实现,专事专用,不具有通用性。
比如我们在写webservice的时候,"任务"主要就是fd和其他一些参数的封装,执行的时候从"任务"里取出fd进行后续操作。
我们的整个逻辑是在一个系统thread_function里执行。所以并不涉及函数栈。这种模式下,每个任务必须是无阻塞的,即便阻塞也会一直卡在那,无法自动切换。
当然,为了传递一些全局参数,比如trace_id,我们需要封装一个context也传过去。
业务框架层面的“通用”协程
这个场景依然是我们自己实现的"协程",但是多了通用性,所以有了更高层面的封装。
但它依然没有到函数栈层面。只能做到用一个独立的线程去执行耗时的任务。也无法自动识别耗时操作并切换,只能手工切换。
具体就是人工根据具体任务名称或特征,判断出是阻塞操作,将其包再包装成一个新“任务”放到一个独立处理耗时任务的线程队列里,并给其加上一个回调函数,等耗时线程处理完了再执行这个回调。
系统层面的协程
系统层面的协程,指的是内置在编程语言里的协程,比如go,比如swoole。
它的任务队里保存的是函数,可以是已存在的函数,也可以是临时的lambda函数。这个函数是有可能阻塞的。当程序判断出阻塞操作的时候,会暂存当前的函数调用栈,切换到下一个执行函数。
具体地说,当我们调用一个函数时,执行流程进入函数;当函数执行完成后,执行流程返回给上层函数。期间,每个函数执行共享一个线程栈;函数返回后栈顶的内容自动回收。比如下面的这段代码:
void fun(void* arg)
{
int a=0; //1
int b=0; //2
doFunc1();//3
int c=a+b; //4
}可能第三步是阻塞的,当程序识别出这里的阻塞后,需要保存当前的状态,切换出去。那么在具体实现上就分为有栈协程和无栈协程。
stackfull 协程
其实有栈协程很好理解,就是当前的函数栈保存起来,并记录其执行位置,然后下次继续执行,但是具体执行层面就没那么容易了。
具体方式大约有三种,这里就不展开了,如有兴趣可以研究一下:
stackless 协程
无栈协程本质上是generator(生成器),简单说,就是函数内部有多个labal和一个状态(state),调用的时候,根据传递进去的state跳转到对应的label段。这个时候默认是无法传递内部参数的,要想传递只能弄一个全局context保存起来,函数里通过context来获取这个参数。
struct Context{
int state; //记录代码执行到哪一行了
....//其他携带信息
}
void doSomething(struct Context* ctx){
//函数的第一部分是要决定跳转到哪里
switch (ctx->state){
case 0: goto Label_0;
case 1: goto Label_1;
case 2: goto Label_2;
case 3: goto Label_3;
case 4: goto Label_4;
case 5: goto Label_5;
}
Label_0:
// doSomething
ctx->state = 1; //进入下一个阶段
return;
Label_1:
// doSomething
ctx->state = 2; //进入下一个阶段
return;
......// 其他labal
}