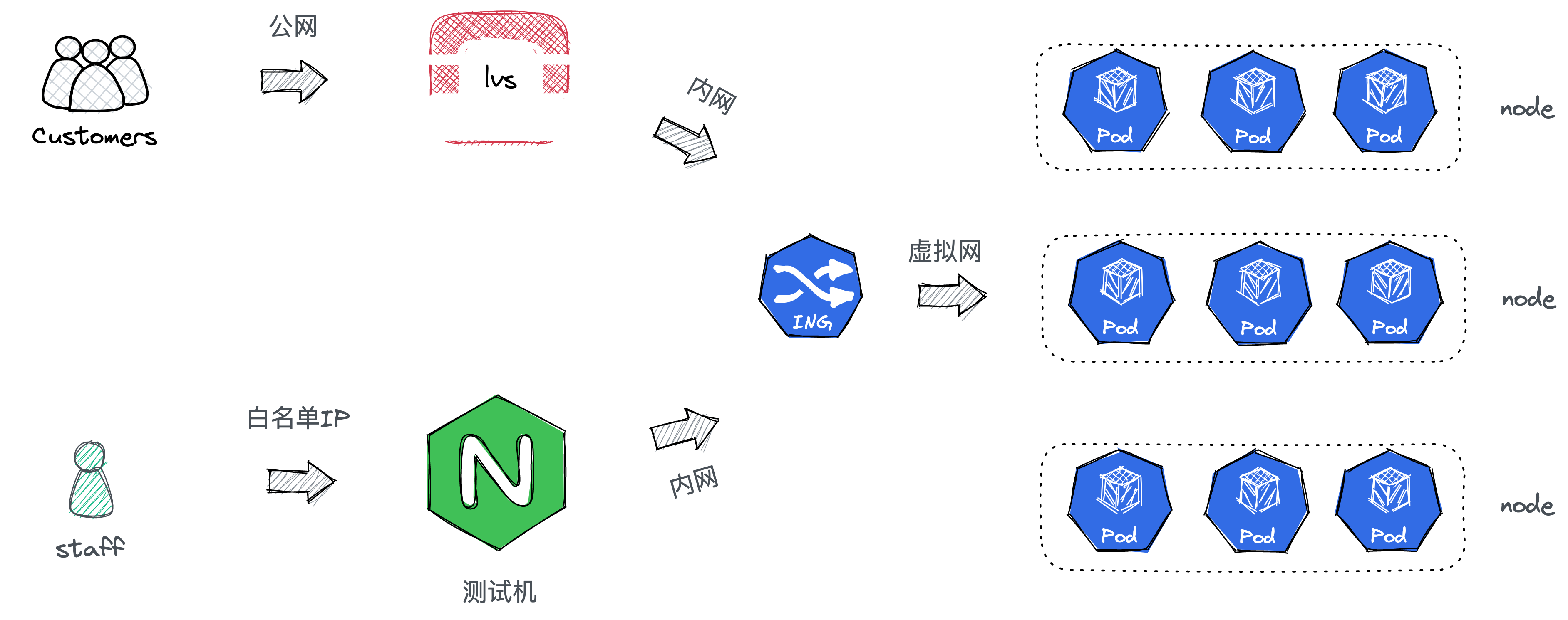
架构
安装
目前有7台机器,其中6台是没有开外网的,1台是测试机,开有1M宽带的外网。k8s部署在6台没有外网的机器上,每台服务器起了一个k8s实例,称之为一个Node。K8s监听的是内网ip。外网无法直接访问k8s集群。
接入
正式环境
每个node通过DaemonSet方式部署了ingress-nginx服务。正式项目通过配置云服务厂商的负载均衡服务器,走内网转发到对应一个Node的ingress监听的端口,然后ingress根据配置的规则转发到对应的Service上。
测试环境
测试服务器起了一个Nginx服务,nginx通过upstream的方式将请求转发到一个k8s Node的ingress,剩下的部分跟正式环境完全一样。测试环境服务器只开了80,443,22端口,而且通过白名单配置,只有指定的ip(段)才能访问这些端口。
内部的一些工具,比如es, kubernetes-dashboard, kibana都部署了一个虚拟域名,这个域名需要改本地hosts访问,通过测试服务器转发到k8s。对于mysql,redis这些宿主机直接部署的,对应客户端必须通过ssh的方式接入。这些访问都收到了访问白名单的限制,只有名单内的IP才能访问。
部署
组件部署
前面提到了,除了测试机,其他服务器都是没有外网的,所以k8s无法正常拉取image。对于k8s组件,可以通过registry.aliyuncs.com/google_containers镜像地址来解决。但是其他的镜像, 比如ingress-nginx,kubernetes-dashbord等镜像和我们业务打包后镜像,就不能通过此方法了。好在阿里云有个ACR服务,我们在有网的环境将镜像拉下来并push到acr,然后在k8s的deployment.yml里把镜像改成acr地址即可。值得注意的是,ace有区域限制,只有处在同一个区域的acr和服务器才能内网互通。
业务部署
常见的方案是集成Jenkins,但是因为没有外网,所以还得再测试环境搭建一个gitlab或Habor,稳定性很难保证.
另一个方案还是利用acr。无论是本地打包后上传到acr,还是直接ace绑定git仓库触发打包同步,都有一个难题,就是无法触发k8s的重新部署,必须去kubernetes-dashboard里操作下,但是在日常开发中,我们不可能给每个开发成员都开kubernetes-dashboard权限。
这个问题卡了2天就没有很好解决,偶然间我在浏览github的时候,右下角推荐了clientt-go,我一下子就来了灵感。我用go写了个service,利用k8s的sdk来操作k8s来重新部署项目。这个服务可以由界面按钮触发,也可以提供一个url当acr的webhook来触发项目重新部署.随便提下,client-go需要在初始化的时候通过clientcmd.RESTConfigFromKubeConfig(kubeconfig)方法传进去配置文件admin.conf,而该文件默认在k8s master服务器/etc/kubernetes/admin.conf里。
附:最近碰到的其他问题
Mysql Cpu 100%
当时一到晚上12点,整个系统就卡死,查看后发现是MySQL的cpu达到100%,排查后发现此时刻并无定时脚本在执行。检查了mysql的日志发现也没有慢查询。后来运营同事告知,因为微信支付每日限额,所以一到12点就有很多用户提现操作。排查了对应的查询,发现有个查询缺一个索引,该表有三十多万条记录,每次查询130ms,慢查询触发阈值最小是1s,所以该查询不会触发慢查询记录,但是如果查得多会将cpu打满。
kubernetes-dashboard 通过http访问
dash-board 的svc暴露的是443端口,pod暴露的是8443端口,默认都是走的https,然而我们统一是由ingress接收外部请求,然后内部通过svc+port的方式转发。所以https并无必要。但是文档里没有取消证书的配置,最后自己摸索发现只需要在文件deployment.yaml里注释或取消---auto-generate-certificates,记得在livenessProbe配置里将scheme也由https改成http。
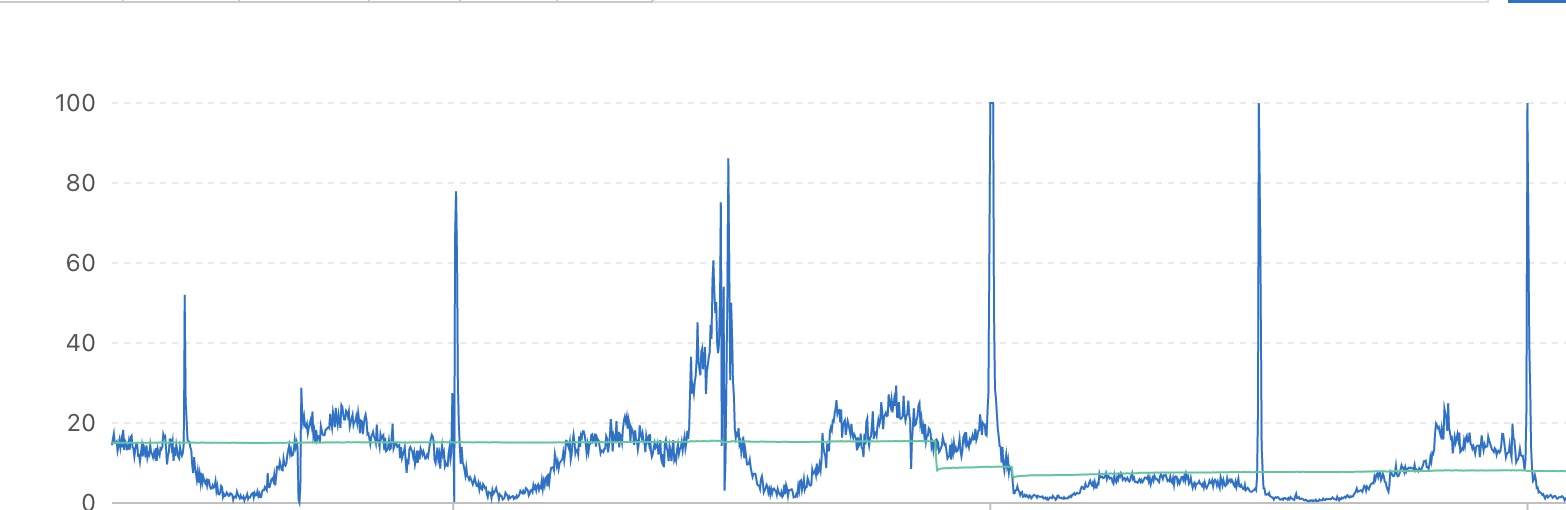
服务器卡死无响应问题修复
当时elk,kafka(zookeeper),k8s这一套装好后,服务器时不时的卡死,通过云服务器的监控面板发现,是磁盘每秒读写达到了上线,我们的云服务器的硬盘选择的是ESSD云盘PL0,实例云盘读写BPS大约是120 M/s,达到这个值服务器就会卡死,ssh连不上,甚至在云服务后台强制重启都会延迟10几分钟。后台监控如下图:

因为当时服务器没有部署业务,不可能有业务读盘操作,所以直觉上就怀疑是内存满了。因服务器的swap早就禁止了。当内存不够的时候,page cache的数据被丢弃,程序只能频繁从硬盘加载文件(比如进程 elf 本身、加载的.so 共享库),导致磁盘读升高。因为当时磁盘读达到上限,ssh一直进不去,只能一直等着云服务器后台监控页的磁盘读取指标降了一点好再登陆,等登陆后查看,发现确实内存占比较高,绝大部分是elasticsearch占的。通过ps -ef | grep elasticsearch命令发现,默认的es的Xms和Xmx配置是总内存的40%多,再加上其他程序占用,内存就满了。差了下文档set-jvm-options)发现可以通过设置环境变量ES_JAVA_OPTS="-Xms2g -Xmx2g"来现在内存占用,使用后就解决了。